
Datos para entrenar robots, el resurgir de la ciencia de datos
El protagonista en el ámbito de la robótica en 2026 no es el hardware ni el software, son los datos para el entrenamiento.


Con la llegada de los LLM parecía que la ciencia de datos se había quedado en segundo plano, ya que la potencia de estos nuevos modelos se logra en los laboratorios de las empresas que les crean, no tanto con el entrenamiento posterior que pudieran darle las organizaciones que los usan. En una época anterior sí que era fundamental poder entrenar los modelos con tus propios datos, pero ahora lo del finetuning parece restringido a los laboratorios de IA más pudientes.
Sin embargo, con el surgimiento de la IA Física nos encontramos en una situación similar previa a la de los LLM en lo que se refiere al entrenamiento de los robots, ya que si queremos usarlos no va a quedar otro remedio que entrenarlos con nuestros propios datos de operación. Quién sabe, quizás pronto podamos tener acceso a modelos generalistas que ya vengan con todo el conocimiento necesario, pero por ahora va a tocar picar piedra y construir nuestra propia base de datos de vídeo en primera persona para entrenar robots.
En este punto vale la pena fijarse en la estrategia que ha compartido NVIDIA en el evento GTC Taipei, donde han explicado que para avanzar en robótica ya no se necesita sólo tener mejores modelos, sino que hay que construir todo el ciclo necesario para que robots, vehículos autónomos y sistemas industriales puedan aprender, simular, validarse y desplegarse en el mundo real.
A este respecto, lo más relevante presentado en el evento sobre IA Física ha sido:
Cosmos 3: modelos abiertos capaces de trabajar con texto, imagen, vídeo, sonido y acción. Su valor no está solo en generar vídeo, sino en ayudar a razonar sobre estados futuros, simular mundos y entrenar sistemas físicos con datos sintéticos.
Alpamayo: una apuesta fuerte por el entrenamiento en bucle cerrado para vehículos autónomos. La idea principal es que el modelo debe aprender de las consecuencias de sus propias decisiones en simulación, no solo imitar datos grabados.
JetPack 7.2: más herramientas para desplegar IA agente en el edge: robots, cámaras, máquinas industriales y dispositivos autónomos. Aquí la cuestión crítica es pasar del laboratorio al hardware real.
Agent Skills: NVIDIA está convirtiendo flujos complejos de simulación, generación de datos, entrenamiento, validación y despliegue en tareas que agentes de IA pueden ejecutar y los desarrolladores pueden revisar.
ovrtx: un SDK para integrar simulación de sensores RTX (cámaras, lidar, radar) en aplicaciones propias, usando OpenUSD y flujos compatibles con simulación, CAD y visualización.
Isaac GR00T Reference Humanoid Robot: de la que hablamos la semana pasada y que es una plataforma integrada para investigación en humanoides, que combina hardware, manos, computación y software. Con el objetivo de que los ingenieros de robótica puedan pasar menos tiempo ensamblando piezas básicas, y dedicar más tiempo investigando políticas y comportamiento.
De esta forma, lo que estamos comprobando día a día a media es que la IA física no avanza sólo gracias al desarrollo de modelos más grandes sino que lo hace a medida que se desarrolla una infraestructura completa para generar datos, simular escenarios raros, entrenar en bucle cerrado, validar comportamientos y desplegar en máquinas reales.
El reto de la recopilación de datos para el entrenamiento de robots
Llegados a este punto hay que insistir de nuevo en la importancia de la recopilación de datos para entrenar los robots y aquí hay que saber que lo ocurrido con los LLM no es extrapolable a los VLA o WAM, ya que actualmente los datos no existen, algo que sí que ocurría con los datos digitales en formato texto e imagen que se usaron para el entrenamiento de ChatGPT y compañía.
Entonces, para entrenar los modelos de IA Física va a ser necesario generar los datos desde cero, a no ser que seamos capaces de encontrar la forma de que los vídeos de youtube o tiktok de gente haciendo cosas también se puedan usar para ello.
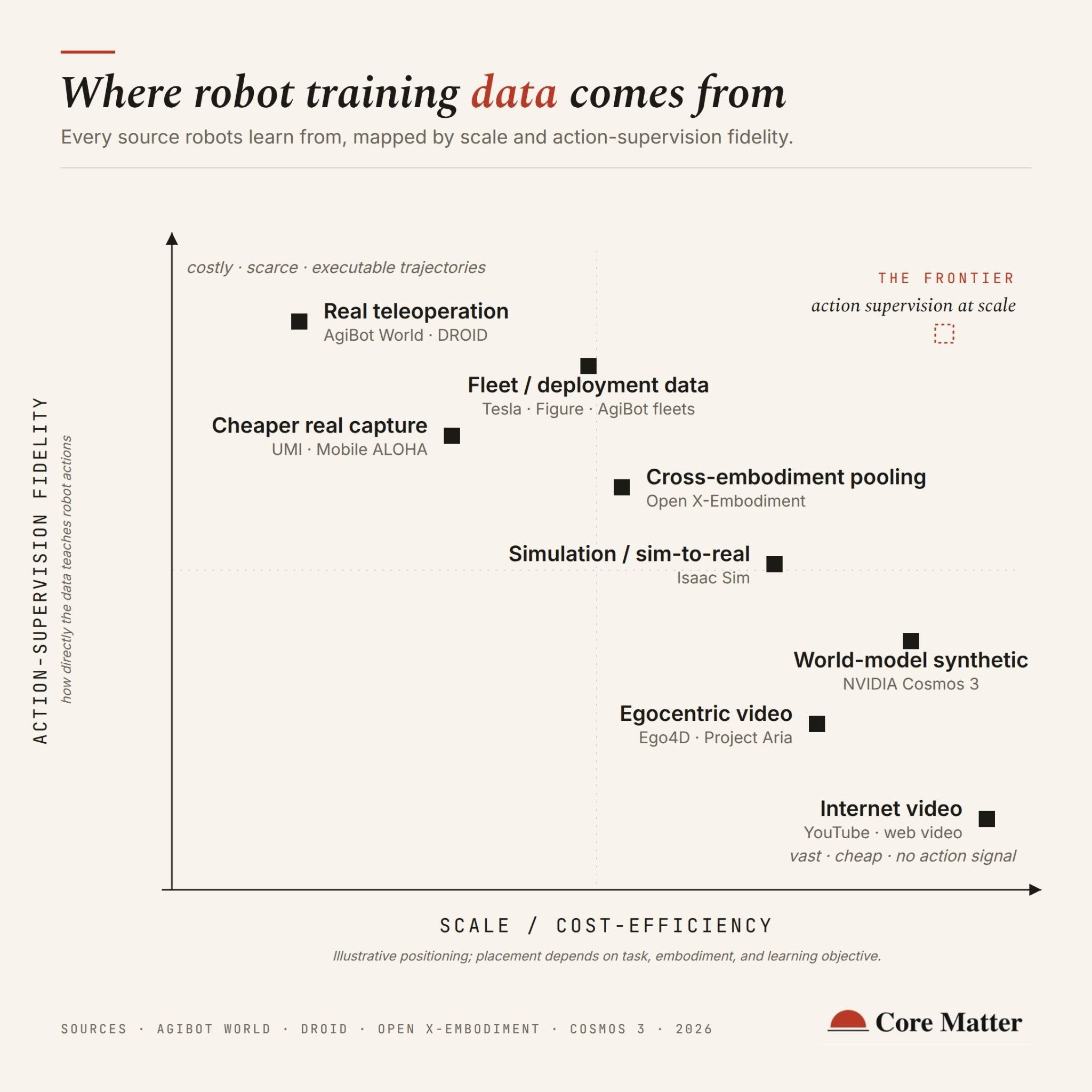
Y las formas actuales en las que la industria trabaja actualmente para captar datos para entrenar robots son:
1. Teleoperación: una persona controla el robot a distancia y este registra todos los movimientos realizados. Es la forma más directa de enseñar habilidades, pero también la más cara, porque cada hora de datos requiere una hora de trabajo humano. Ejemplos: AgiBot World, DROID.
2. Simulación manual: en lugar de controlar directamente el robot, se registran los movimientos de una persona utilizando dispositivos más simples y económicos que simulan las manos del robot. Esto reduce mucho el coste de recopilación de datos al no tener que trabajar directamente con el robot, aunque luego hay que traducir los movimientos humanos a las articulaciones del robot. Ejemplos: Mobile ALOHA, UMI.
3. Datos de robots desplegados: cuando los robots empiezan a trabajar en fábricas, almacenes o entornos reales, generan datos continuamente. Cada error, cada excepción y cada tarea realizada se convierte en material de entrenamiento. Tesla espera aprovechar millones de horas de experiencia acumuladas por sus vehículos autónomos y futuros robots Optimus. Figure también está siguiendo esta estrategia.
4. Simulación. Los robots aprenden dentro de entornos virtuales antes de enfrentarse al mundo real. La ventaja es grande ya que se pueden generar millones de horas de experiencia a muy bajo coste. Sin embargo, el problema es que la física simulada todavía no reproduce perfectamente la realidad. Aspectos como la fricción, los deslizamientos o los contactos complejos siguen siendo difíciles de modelar. Ejemplos: NVIDIA Isaac Sim, Genesis.
5. Vídeo en primera persona: consiste en grabar lo que ve una persona mientras trabaja. Es mucho más fácil obtener miles de horas de este tipo de vídeos que teleoperar robots. El inconveniente es que muestran lo que ocurre, pero no contienen directamente las acciones robóticas que habría que ejecutar. Ejemplos: Ego4D, Project Aria.
En este punto vale la pena detenerse en el trabajo que ha realizado la startup Gilabs que ha puesto a la venta el dispositivo EGO1 que se presenta como el primer casco de captura egocéntrica para IA Física, un dispositivo que transforma sin esfuerzo las actividades en primera persona, especialmente las manipulaciones, en datos de entrenamiento para modelos fundamentales.
6. Vídeo de internet: YouTube, TikTok y otras plataformas contienen una cantidad inmensa de información sobre cómo interactúan los humanos con el mundo. Es la fuente más barata y escalable ya que permite observar objetos, herramientas, tareas y situaciones muy diversas. Sin embargo, normalmente no incluye información sobre fuerzas, trayectorias exactas o movimientos articulares necesarios para controlar un robot.
7. Datos sintéticos generados por modelos del mundo: Aquí aparece una de las líneas más prometedoras. En lugar de limitarse a simular gráficos, los modelos del mundo intentan predecir cómo evolucionará físicamente una situación cuando el robot actúe. Si estos sistemas alcanzan suficiente precisión, podrían generar enormes cantidades de experiencia sintética sin necesidad de recopilar tantos datos reales. Es una idea muy alineada con la evolución desde los VLA hacia los World Models que ya estamos viendo en robótica. Ejemplo: NVIDIA Cosmos.
Estado actual de desarrollo de los modelos del mundo
“El lenguaje proporcionó a las máquinas una forma de hablar sobre ese mundo. Los modelos del mundo son la manera en que las máquinas finalmente llegarán a comprenderlo, imaginarlo, razonar con él e interactuar con él”.
Hablando de modelos del mundo para el entrenamiento de robots, resulta que la gran Fei-Fei Li acaba de regalarnos un nuevo artículo donde explica cómo está evolucionando la construcción de los modelos del mundo, así que vamos a comentarlo por aquí porque resulta de lo más interesante.
Lo que la doctora nos explica es que el término “modelo del mundo” se está usando para demasiadas cosas distintas. Y esto empieza a ser un problema, porque no es lo mismo un modelo que genera vídeos espectaculares, que un sistema capaz de simular la física de una escena, que un modelo que ayuda a un robot a decidir qué acción debe ejecutar.
Dicho de forma sencilla: no todo lo que parece entender el mundo lo entiende realmente.
Por ejemplo, un modelo puede generar una ciudad preciosa vista desde un dron, con edificios, calles, árboles y coches, pero si intentamos recorrer esa misma ciudad desde el suelo puede que todo empiece a romperse. Las fachadas no encajan, las calles no tienen continuidad, las proporciones fallan o los objetos no tienen una geometría coherente.
Eso para hacer un vídeo puede ser suficiente, pero para entrenar un robot no lo es.
Un robot no necesita sólo una imagen convincente del mundo. Necesita una representación útil del mundo. Necesita saber dónde están los objetos, qué forma tienen, cuánto ocupan, cómo se mueven, qué pasa si los empuja, si pesan, si resbalan, si se rompen, si bloquean el paso o si pueden agarrarse.
Por eso Fei-Fei Li y su equipo de World Labs proponen distinguir tres funciones distintas dentro de los modelos del mundo: renderizar, simular y planificar.
El renderizador genera lo que vemos.
El simulador representa cómo funciona el mundo.
El planificador decide qué acción debería ejecutar un agente dentro de ese mundo.
Y esta distinción es fundamental para entender hacia dónde va la IA Física. Por lo tanto hay que seguir muy atentos al trabajo que realiza World Labs y el resto de empresas que trabajan en el desarrollo de los WAM, porque de ellas depende el futuro de la robótica.
Más noticias de robótica e IA Física
📦 Amazon enseña a Proteus, su robot móvil autónomo para almacenes, a obedecer instrucciones en lenguaje natural y prepara su llegada a Europa en 2027 dentro de una inversión logística de 10.000 millones de euros. Esto no va solo de AMRs: apunta a una capa donde el operario expresa una intención y el sistema decide prioridad, ruta y momento de ejecución, acercando la robótica logística a interfaces de trabajo más naturales y menos programadas.
🧪 Hugging Face presenta LeLab, una interfaz gráfica sobre LeRobot para configurar robots, teleoperar, recoger datasets, entrenar políticas localmente o en GPUs cloud con HF Jobs y desplegar modelos en el robot. De momento está centrado en SO-ARM101, pero el movimiento es relevante porque reduce la fricción entre hardware barato, datos propios y aprendizaje por imitación.
🎮 Roblox compra Morpheus AI para reforzar Roblox Reality, su arquitectura de mundos generativos basada en modelos de vídeo y datos 3D. Aunque esté dedicado a los videojuegos, la señal importa para robótica porque los mundos interactivos, persistentes y generables en tiempo real son parte de la misma batalla técnica que la simulación física: pasar de renderizar escenas bonitas a construir entornos donde un agente pueda actuar.
💰 Generalist AI levanta 400 millones de dólares, superando los 500 millones captados anteriormente, para acelerar sus modelos de IA física y escalar su motor de datos, cómputo e infraestructura de entrenamiento. La compañía afirma que GEN-1 ya alcanza tracción comercial en tareas diestras con alta fiabilidad. Así vemos que la financiación empieza a concentrarse en laboratorios que quieren convertir datos físicos, modelos grandes y despliegue real en un ciclo de mejora.
🧠 1X lanza su World Model Lab, liderado por Sam Sinha, ex investigador de Luma AI, para preentrenar modelos del mundo orientados a humanoides autónomos. La tesis que plantea 1X es que la robótica no se resolverá solo afinando modelos existentes, sino entrenando desde el inicio con vídeo web, vídeos egocéntricos, simulación, teleoperación, y datos de NEO despliegue real.
🤖 NVIDIA trabaja con LG en robots humanoides y centros de datos, según explicó Jensen Huang tras reunirse con el presidente de LG Group en Seúl. La colaboración apunta a motores, sistemas mecánicos y arquitectura de data centers, reforzando la idea de que la IA física no será solo software. También exigirá alianzas entre chips, infraestructura, mecatrónica y fabricantes industriales con capacidad de producción.
🏠 Hello Robot sigue una vía distinta al humanoide típico con Stretch 4, presentando un robot doméstico de asistencia que trabaja en casas reales, con personas y un humano en el bucle. Su precio ronda los 30.000 dólares y la primera producción ya está vendida. Esto anticipa que en robótica doméstica puede ganar quien acumule horas reales de uso seguro, no quien prometa más autonomía en demos.
🏭 Standard Bots recauda 200 millones de dólares a una valoración de 1000 millones y afirma que ya es el mayor fabricante estadounidense de robots industriales “AI-native” y cita clientes como Sunoco, Lockheed Martin y NASA. “Creemos que los robots nativos de IA son la herramienta de poder esencial del siglo XXI —la herramienta que impulsará la fabricación estadounidense y ayudará a cada trabajador estadounidense a ser una fuerza en el trabajo”